Benchmarking
Command-line utilities
One of the advantage of using fluidfft is to be able to use the fastest fft library for a particular problem and in a particular (super)computer.
We provide command-line utilities to easily run and analyze benchmarks. You can for example run the commands:
fluidfft-bench -h
# 2d
fluidfft-bench 1024 768
fluidfft-bench 1024 -d 2
mpirun -np 2 fluidfft-bench 1024 -d 2
# 3d
fluidfft-bench 32 48 64
fluidfft-bench 128 -d 3
mpirun -np 2 fluidfft-bench 128 -d 3
Once you have run many benchmarks (to get statistics) for different numbers of processes (if you want to use MPI), you can analyze the results for example with:
fluidfft-bench-analysis 1024 -d 2
Benchmarks on Occigen
Occigen is a GENCI-CINES HCP cluster.
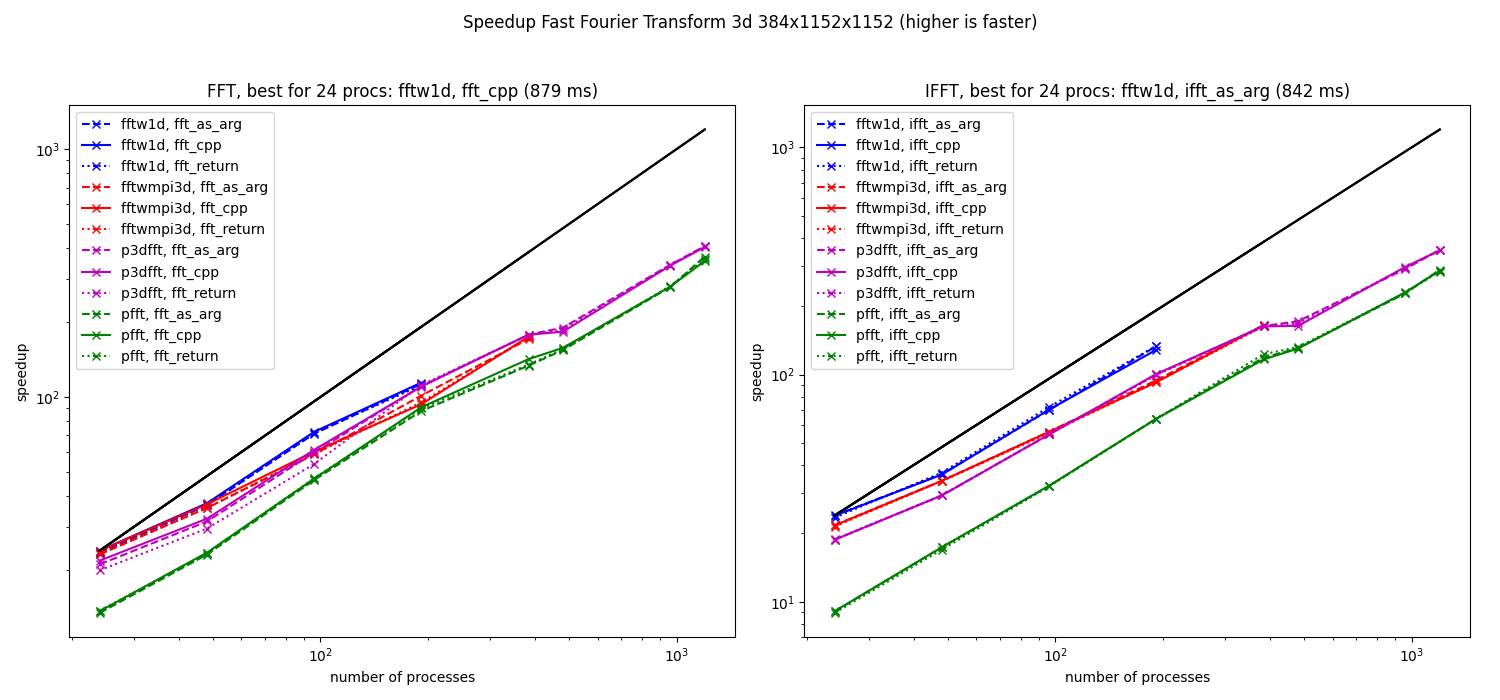
Speedup computed from the median of the elapsed times for 3d fft (384x1152x1152, left: fft and right: ifft) on Occigen.
For every FFT classes available for the resolution and for the two tasks fft and ifft, three functions are used and compared (see the legends):
“fft_cpp” (continuous lines): benchmark of the C++ function from the C++ code. No memory allocation.
“fft_as_arg” (dashed lines): benchmark of a Python method
fft_as_argfrom Python. As for the C++ code, the second argument of this method is an array to contain the result of the transform, so no memory allocation is needed.“fft_return” (dotted lines): benchmark of a Python method
fftfrom Python. No array is provided to the function to contain the result so a numpy array is created and then returned by the function.
The fastest methods are fftw1d (which is limited to 192 cores) and p3dfft.
The benchmark is not sufficiently accurate to measure the cost of calling the functions from Python (difference between continuous and dashed lines, i.e. between pure C++ and the “as_arg” Python method) and even the creation of the numpy array (difference between the dashed and the dotted line, i.e. between the “as_arg” and the “return” Python methods).
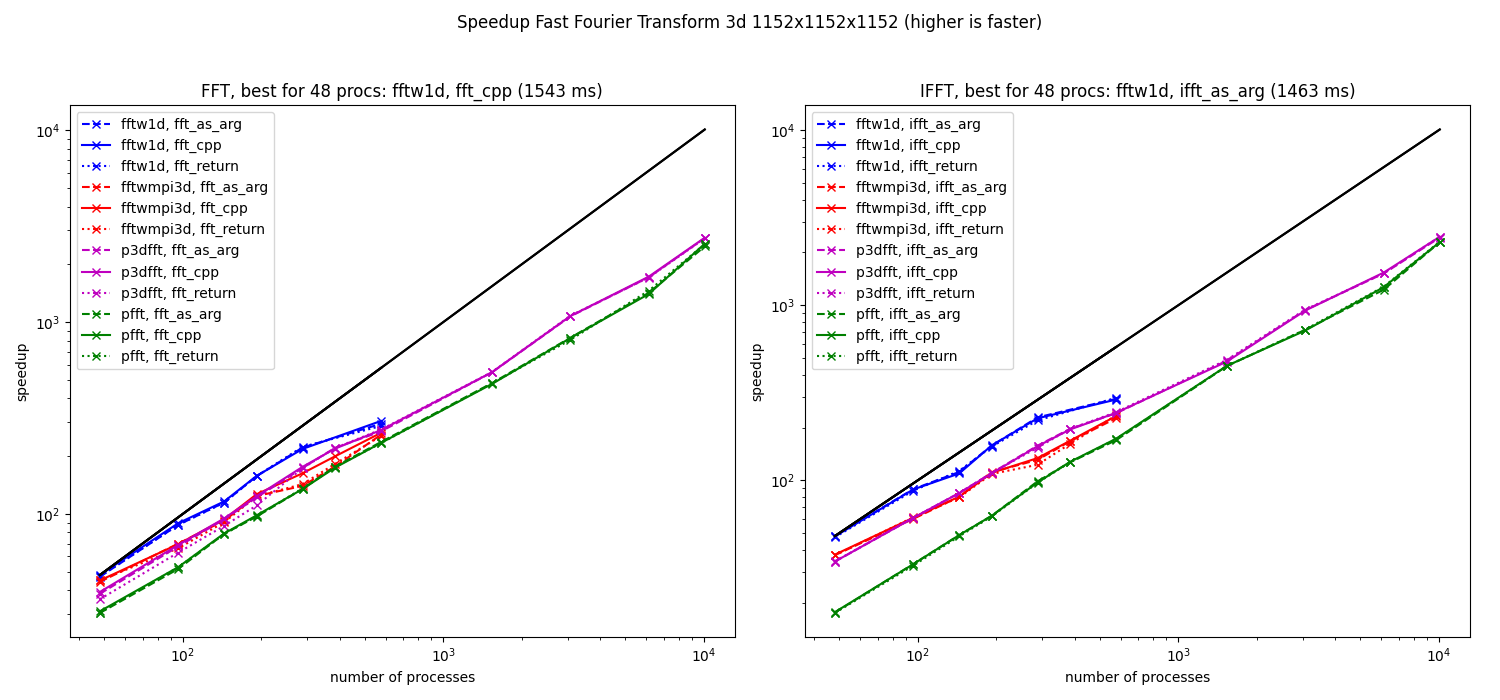
Speedup computed from the median of the elapsed times for 3d fft (1152x1152x1152) on Occigen.
For this resolution, the fftw1d is also the fastest method when using only few cores and it can not be used for more that 576 cores. The faster library when using more cores is also p3dfft.
Benchmarks on Beskow
Beskow is a Cray machine running Intel processors.
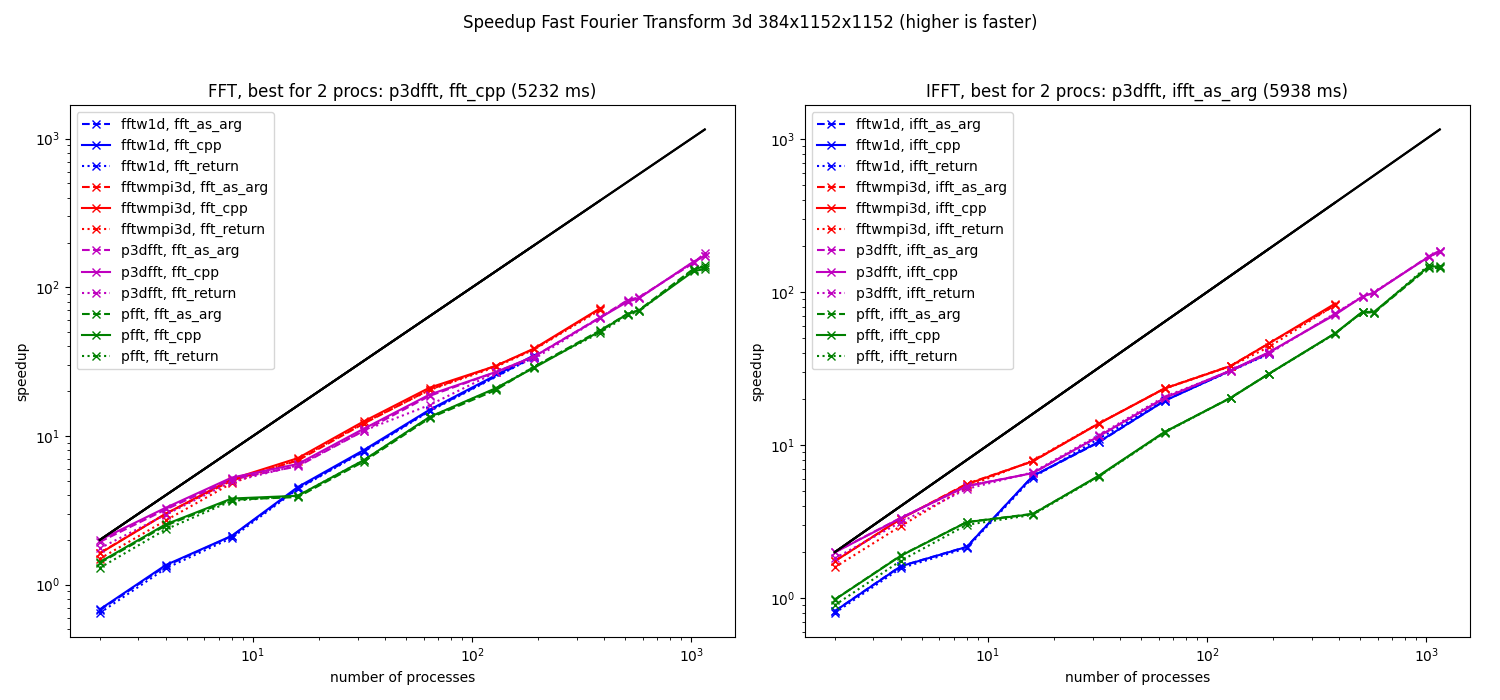
Speedup computed from the median of the elapsed times for 3d fft (384x1152x1152) on Beskow.
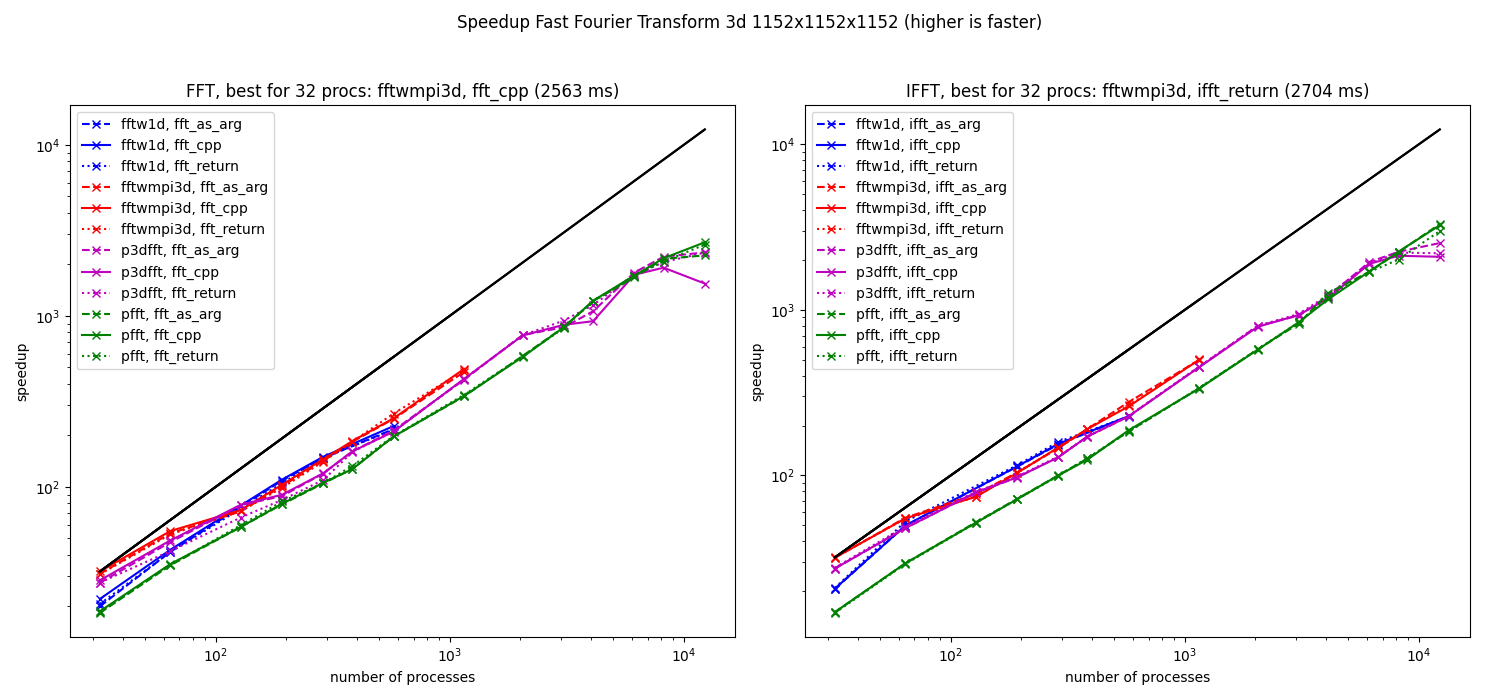
Speedup computed from the median of the elapsed times for 3d fft (1152x1152x1152) on Beskow.
Benchmarks on a LEGI cluster
We run some benchmarks on Cluster8 (2015, 12 nodes Xeon DELL C6320, 20 cores per node).
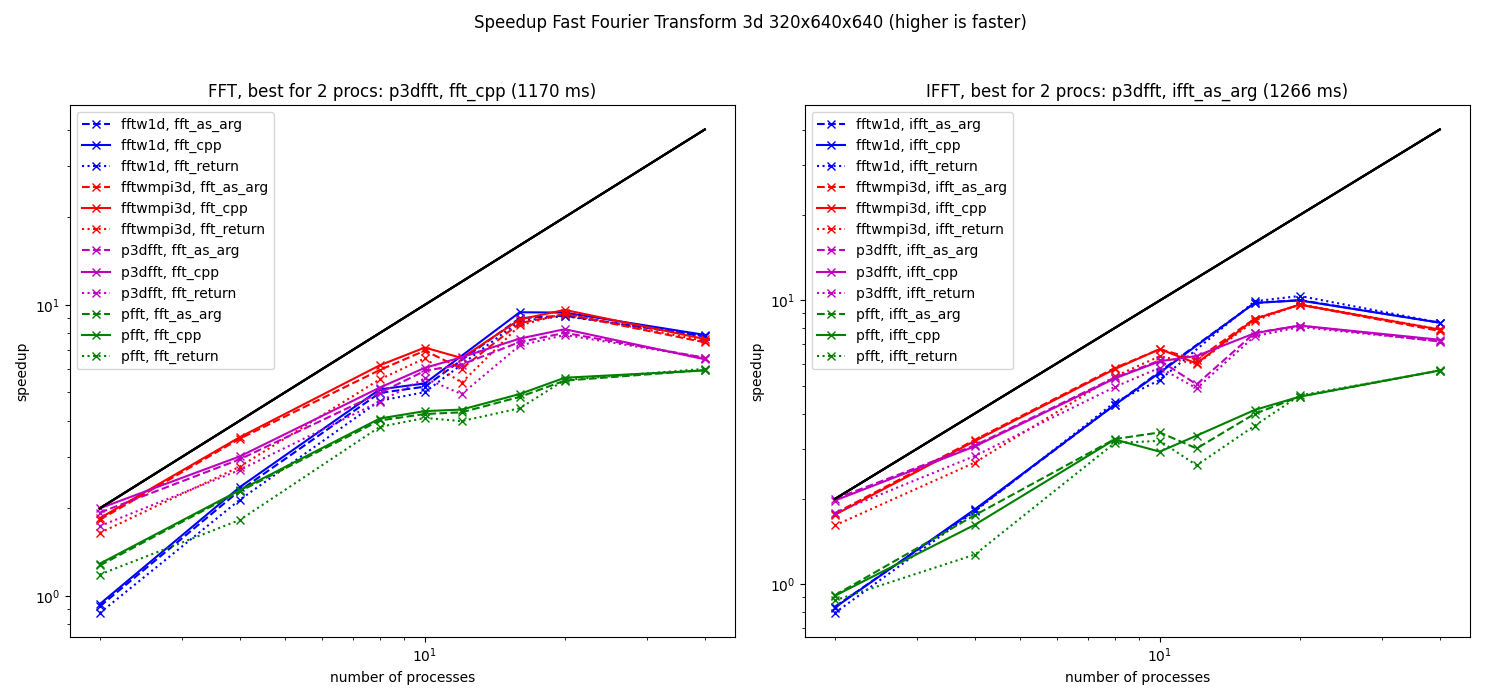
Speedup computed from the median of the elapsed times for 3d fft (320x640x640) at LEGI on cluster8.
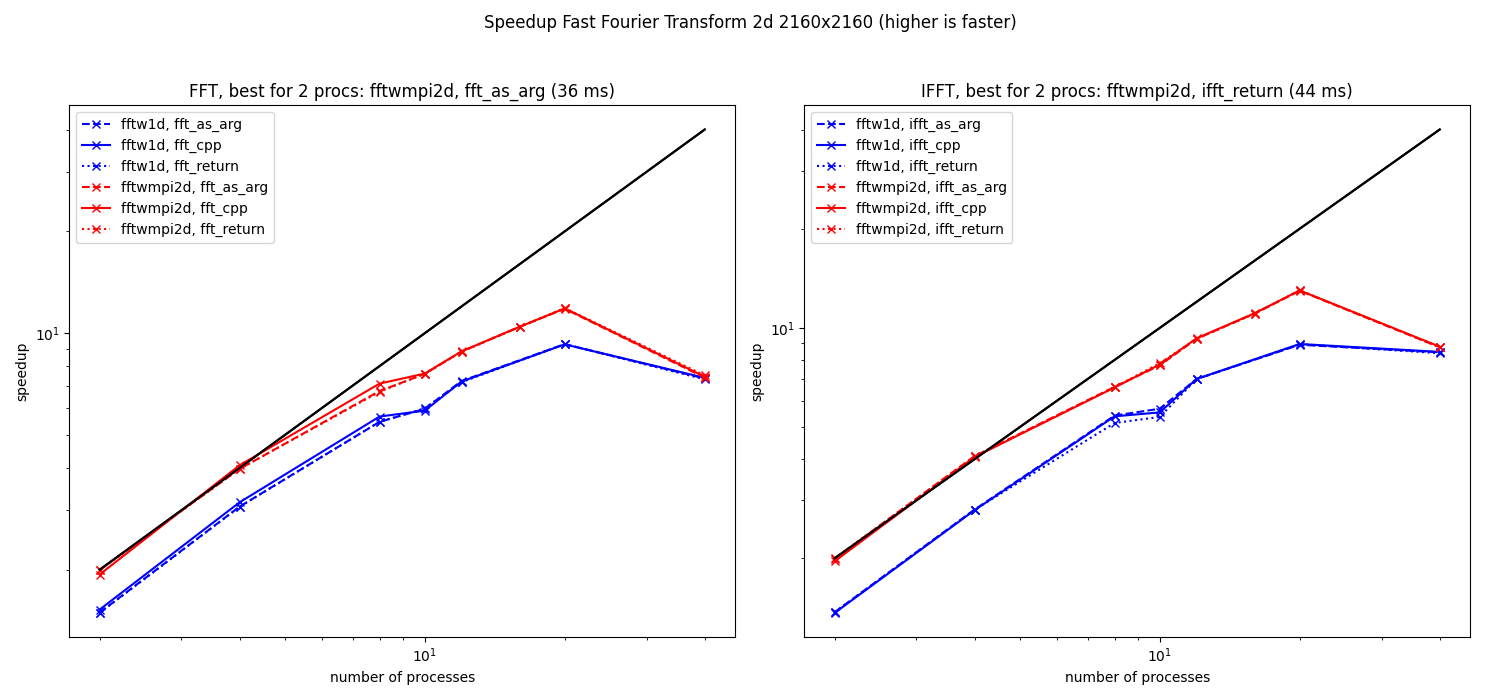
Speedup computed from the median of the elapsed times for 2d fft (2160x2160) at LEGI on cluster8.
We see that the scaling is not far from linear for intra-node computations. In contrast, the speedup is really bad for inter-node computations.